NAS变AI私人工作站:群晖私有化DeepSeek与智能文档管理全攻略
含完整 Docker 命令 · 本地大模型 + 扫描件 AI 归档 + MCP-SynoLink 文件操控
手把手教你在群晖NAS上部署Ollama+DeepSeek本地大模型、Paperless-AI智能文档归档和MCP-SynoLink让AI直接操控文件,附完整Docker命令。数据完全不出局域网。
概述

一、为什么要在NAS上私有化运行AI?
2026年,用AI处理个人文件依然有一个根本矛盾:要让AI读懂你的文件,通常就必须把文件上传到云端。
家庭照片、个人日记、公司合同、财务报表——这些内容,你真的愿意上传给OpenAI或任何一家你不了解的AI公司吗?
群晖NAS爱好者社区给出了另一条路:把AI模型直接跑在NAS上,数据永不出门。本文手把手介绍三套经过验证的方案:
- Ollama + DeepSeek-R1:群晖本地运行大语言模型,私密问答 + 文件分析
- Paperless-AI + Paperless-NGX:扫描文件AI自动识别、分类、打标签
- MCP-SynoLink:让AI助手(Claude)直接操控群晖文件系统
二、方案一:Ollama + DeepSeek-R1 — 在群晖上运行本地大模型
2.1 为什么选DeepSeek + Ollama?
DeepSeek-R1(深度求索,2025年1月发布):完全开源、可商用,推理能力与OpenAI o1相当,国内用户使用无网络障碍,是目前本地部署性价比最高的中文大模型。
Ollama:最易用的本地大模型运行框架,内置 REST API 服务(兼容 OpenAI 格式),天然适配群晖 Container Manager(Docker)环境,且可与群晖 AI Console 1.2 直接对接。
2.2 选择合适的模型版本
| 模型版本 | 存储空间 | 运行内存 | 响应速度 | 推荐机型 |
|---|---|---|---|---|
| deepseek-r1:1.5b | ~1GB | 约3GB | 15 tokens/秒 | 入门J4125机型 |
| deepseek-r1:7b | ~4.7GB | 约8GB | 8 tokens/秒 | RS3626xs(默认 8GB ECC,2U 机架) |
| deepseek-r1:14b | ~9GB | 约16GB | 较慢 | 高配x86机型 |
| deepseek-r1:70b | ~40GB | 约48GB | 2 tokens/秒 | RS3626xs 升配 48GB ECC |
中小企业用户推荐7b版本:8GB内存可流畅运行,中文对话准确率远高于1.5b。
2.3 【完整操作步骤 + Docker命令】
前提条件:
- DSM 7.x,已安装 Container Manager 套件
- SSH 已开启(DSM → 控制面板 → 终端机与SNMP → 开启SSH)
第一步:SSH登入群晖,创建目录
# 登入群晖(替换为你的NAS IP)
ssh admin@192.168.1.100 -p 22
# 创建 Ollama 数据目录
mkdir -p /volume1/docker/ollama/data
cd /volume1/docker/ollama
第二步:启动 Ollama 容器
docker run -d \
--restart unless-stopped \
--name ollama \
-p 11434:11434 \
-v /volume1/docker/ollama/data:/root/.ollama \
ollama/ollama
参数说明:
-p 11434:11434:映射API端口,局域网内其他设备可访问-v ...:/root/.ollama:将模型文件持久化存储到NAS硬盘--restart unless-stopped:NAS重启后自动恢复
第三步:进入容器,下载DeepSeek模型
# 进入 Ollama 容器
docker exec -it ollama /bin/bash
# 下载7b版本(推荐,约4.7GB)
ollama pull deepseek-r1:7b
# 或下载1.5b版本(入门机型)
ollama pull deepseek-r1:1.5b
# 同时下载文本向量模型(Paperless-AI需要)
ollama pull nomic-embed-text
# 退出容器
exit
下载时间取决于网速,7b模型国内通常需要15-40分钟。下载完成后模型文件持久化存储在 /volume1/docker/ollama/data,NAS重启后无需重新下载。
第四步:验证Ollama运行状态
# 在NAS上测试API(返回模型列表即成功)
curl http://localhost:11434/api/tags
# 快速测试对话
curl http://localhost:11434/api/generate -d '{
"model": "deepseek-r1:7b",
"prompt": "用一句话介绍群晖NAS",
"stream": false
}'
第五步:部署 Open WebUI(可视化对话界面)
docker run -d \
--restart unless-stopped \
--name open-webui \
-p 3000:8080 \
-e OLLAMA_BASE_URL=http://[NAS-IP]:11434 \
-v /volume1/docker/open-webui:/app/backend/data \
ghcr.io/open-webui/open-webui:main
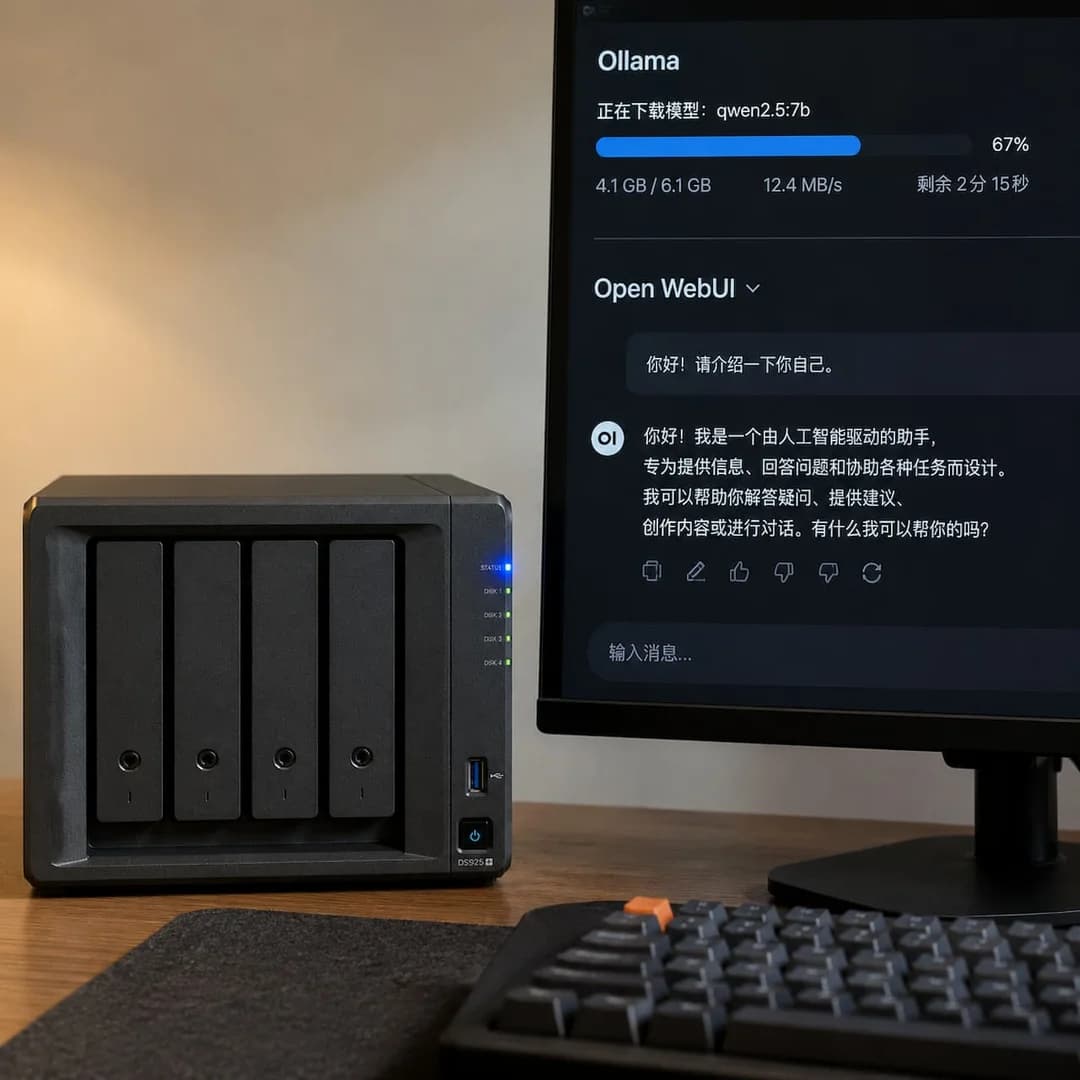
部署完成后,浏览器访问 http://[NAS-IP]:3000,首次访问需注册管理员账号。登录后在界面中选择 deepseek-r1:7b 模型即可开始对话。
第六步(可选):接入群晖AI Console
若已安装 AI Console 1.2,可将 Ollama 作为本地AI后端:
- 打开 AI Console → AI Providers → Add
- Provider 选择 Custom
- API Base URL 填入:
http://localhost:11434/v1 - API Key:留空或填任意字符
- Model Name:
deepseek-r1:7b - Test Connection → Save
完成后,MailPlus 和 Office 的AI功能将调用本地 DeepSeek,数据完全不出局域网。
2.4 本地大模型能对NAS文件做什么?
在 Open WebUI 的对话框中,可以上传文件让 DeepSeek 分析:
- 上传PDF → "总结这份合同的主要条款和风险点"
- 上传Excel/CSV → "哪个月销售额最高?找出异常数据"
- 上传Word → "把这份中文报告翻译成英文,保留格式"
- 上传代码文件 → "解释这段Python代码的逻辑并找出潜在bug"
7b版本实测:中文文档摘要准确率约88-92%,基本满足日常使用需求。
三、方案二:Paperless-AI — AI自动消灭"扫描件堆"
3.1 场景:你是否有一堆叫 scan_001.pdf 的文件?
很多家庭和小企业用NAS存储大量扫描件:合同、发票、保单、医疗记录。这些文件往往以日期随机命名,查找时全靠记忆,完全无法按内容搜索。
Paperless-AI 是基于 Paperless-ngx 的AI增强方案,可将扫描件处理完全自动化:
纸质文件 → 扫描/拍照 → 上传指定文件夹
→ OCR识别文字 → AI分析内容
→ 自动打标签(发票/合同/保单)
→ 自动重命名(2024-03_招商银行_信用卡账单.pdf)
→ 归入对应文件夹 → 可全文搜索
3.2 技术原理
Paperless-AI的工作流程分三层:
① OCR层(文字识别) Paperless-ngx内置OCR引擎,自动识别扫描件中的文字内容,使PDF变为可搜索文件。
② AI分析层(理解与分类) AI模型(可接入本地Ollama运行的DeepSeek/Llama,也可对接OpenAI等云端服务)读取OCR结果,执行:文档类型识别(合同/发票/保单/医疗记录/收据等)、关键信息提取(日期、金额、当事人)、自动生成标签、建议归档文件夹。
③ 归档层(执行存储) 根据AI分析结果,自动将文件归入对应文件夹,按规范重命名,并写入可搜索的元数据。
3.3 【完整操作步骤 + Docker命令】
前提条件:
- 已部署 Ollama(方案一)或有可用的 OpenAI API Key
- 已安装 Container Manager
- 建议先备份文档,Paperless-AI 会修改文件元数据
第一步:在 File Station 创建目录
打开 DSM → File Station → docker 文件夹,新建文件夹:paperlessngxai(全小写)
第二步:部署 Paperless-NGX(核心系统)
在 /volume1/docker/paperlessngxai/ 目录下创建 docker-compose.yml:
version: "3.4"
services:
broker:
image: docker.io/library/redis:7
restart: unless-stopped
volumes:
- /volume1/docker/paperlessngxai/redisdata:/data
db:
image: docker.io/library/postgres:15
restart: unless-stopped
volumes:
- /volume1/docker/paperlessngxai/pgdata:/var/lib/postgresql/data
environment:
POSTGRES_DB: paperless
POSTGRES_USER: paperless
POSTGRES_PASSWORD: paperless
webserver:
image: ghcr.io/paperless-ngx/paperless-ngx:latest
restart: unless-stopped
depends_on:
- db
- broker
ports:
- "8777:8000"
volumes:
- /volume1/docker/paperlessngxai/data:/usr/src/paperless/data
- /volume1/docker/paperlessngxai/media:/usr/src/paperless/media
- /volume1/docker/paperlessngxai/export:/usr/src/paperless/export
- /volume1/docker/paperlessngxai/consume:/usr/src/paperless/consume
environment:
PAPERLESS_REDIS: redis://broker:6379
PAPERLESS_DBHOST: db
PAPERLESS_OCR_LANGUAGE: chi_sim+eng
PAPERLESS_SECRET_KEY: 替换为随机字符串
PAPERLESS_TIME_ZONE: Asia/Shanghai
PAPERLESS_OCR_MODE: skip_noarchive
USERMAP_UID: "1026"
USERMAP_GID: "100"
在 Container Manager 中选择 项目 → 新建 → 从compose文件创建,粘贴上述内容后启动。
部署完成后访问 http://[NAS-IP]:8777,创建管理员账号。
第三步:获取 Paperless-NGX API Token
- 登录 Paperless-NGX → 右上角头像 → 我的个人资料
- 找到 API Auth Token 区域
- 点击刷新图标生成 Token,复制备用
第四步:部署 Paperless-AI 容器
docker run -d \
--restart unless-stopped \
--name paperless-ai \
-p 3747:3000 \
clusterzx/paperless-ai
第五步:配置 Paperless-AI
浏览器访问 http://[NAS-IP]:3747/setup,填写以下配置:
# 用户设置
Username: 你的管理员用户名
Password: 你的密码
# Paperless-NGX 连接
Paperless-ngx API URL: http://[NAS-IP]:8777 ← 末尾不加斜杠
API Token: (第三步复制的Token)
# AI配置(使用本地Ollama)
AI Provider: Ollama(Local LLM)
Ollama API URL: http://[NAS-IP]:11434 ← 末尾不加斜杠
Ollama Model: deepseek-r1:7b
# 标签设置
AI-Processed Tag: ai-processed
填写完成后点击 Save Configuration,等待服务重启(约30秒)。
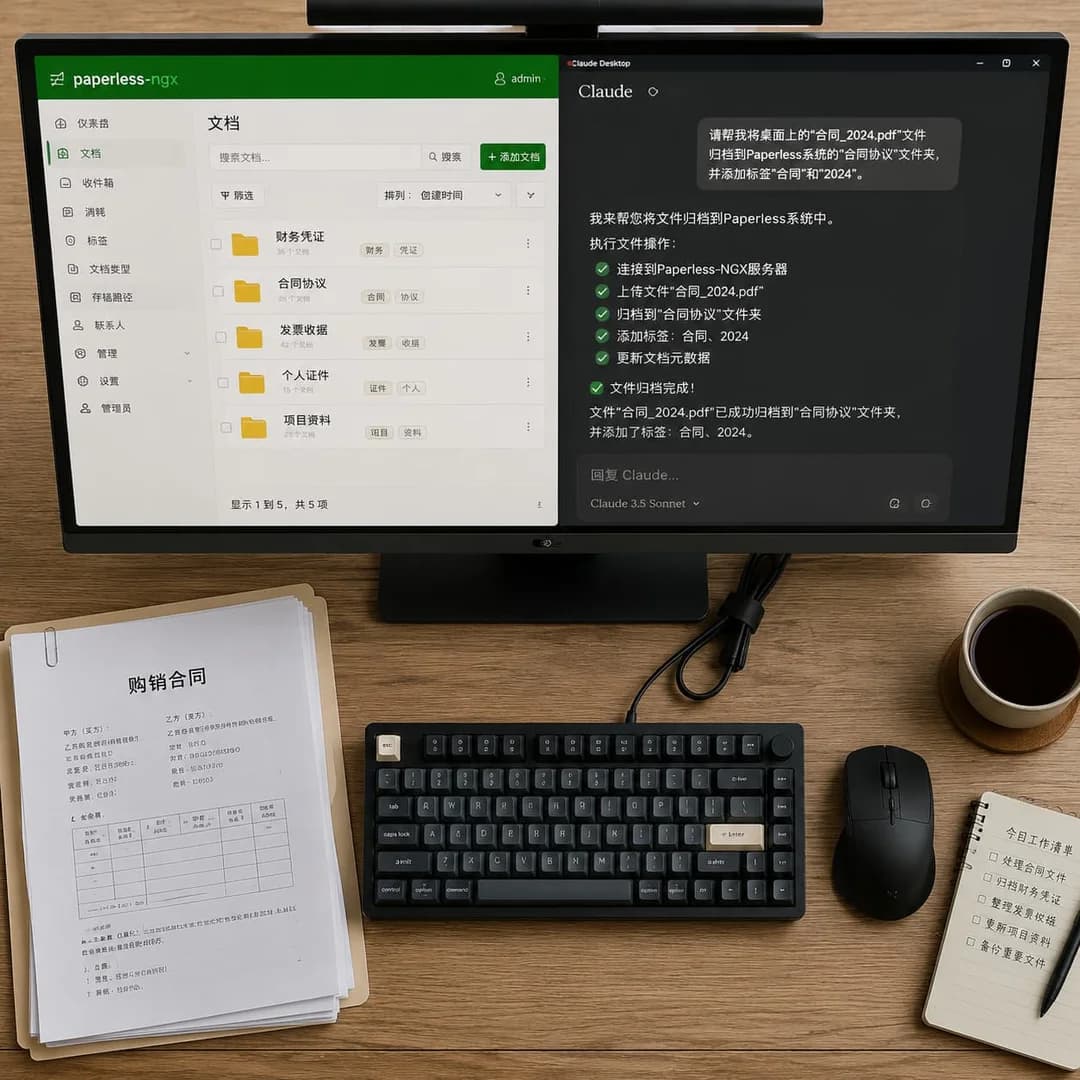
第六步:使用 Paperless-AI 处理文档
- 将扫描文件放入
/volume1/docker/paperlessngxai/consume文件夹(Paperless-NGX 自动检测并导入) - 打开
http://[NAS-IP]:3747/dashboard - 选择 Manual → 在文件列表中勾选需要AI处理的文件
- 点击 Analyze → AI将自动分析内容、建议标签、建议标题
- 确认或修改建议后点击 Apply
也可开启全自动模式:新导入的文件自动触发AI分析,无需手动操作。
四、方案三:MCP-SynoLink — 让AI助手直接接管群晖文件操作
4.1 什么是MCP协议?
2024年11月,Anthropic发布了MCP(Model Context Protocol),核心思想是:让AI助手不再只是"对话",而是能直接调用外部工具执行实际操作。截至2025年,社区已创建超过1000个MCP服务器。
MCP-SynoLink 是专为群晖DSM设计的MCP服务器,让 Claude Desktop 等AI助手可以直接操控群晖文件系统——搜索文件、上传下载、创建文件夹、生成分享链接等,支持DSM 6.0+。
4.2 MCP-SynoLink 可执行的操作
| 操作类别 | 具体功能 |
|---|---|
| 文件浏览 | 列出文件夹内容、递归搜索文件 |
| 文件操作 | 上传、下载、创建文件夹、删除、重命名/移动 |
| 分享管理 | 创建分享链接、列出现有分享 |
| 系统信息 | 查看存储配额、服务器状态 |
| 认证 | 登录/登出群晖DSM账号 |
4.3 【完整操作步骤 + 配置命令】
前提条件:
- 本地电脑已安装 Node.js 18+ 或 Docker
- 已安装 Claude Desktop(Anthropic官方桌面应用)
- 群晖DSM 6.0+
第一步:下载并构建 MCP-SynoLink
# 克隆项目到本地电脑(非NAS)
git clone https://github.com/Do-Boo/MCP-SynoLink.git
cd MCP-SynoLink
# 安装依赖并构建
npm install
npm run build
第二步:在群晖创建专用DSM账号
安全最佳实践:不要使用 admin 账号,创建权限最小的专用账号。
- DSM → 控制面板 → 用户与群组 → 新增用户
- 用户名:
mcp-agent(或任意名称) - 只开放需要操作的共享文件夹权限(按需分配读写权限)
- 不勾选管理员权限
第三步:配置 Claude Desktop
找到 Claude Desktop 配置文件:
- macOS:
~/Library/Application Support/Claude/claude_desktop_config.json - Windows:
%APPDATA%\Claude\claude_desktop_config.json
方案A:Node.js 方式(推荐)
{
"mcpServers": {
"synolink": {
"command": "node",
"args": [
"/你的路径/MCP-SynoLink/dist/index.js",
"http://192.168.1.100:5000",
"mcp-agent",
"你的密码"
]
}
}
}
方案B:Docker 方式
# 先构建镜像(一次性操作)
cd MCP-SynoLink
docker build -t mcp/synolink .
在 claude_desktop_config.json 中添加:
{
"mcpServers": {
"synolink": {
"command": "docker",
"args": [
"run", "-i", "--rm",
"mcp/synolink",
"http://192.168.1.100:5000",
"mcp-agent",
"你的密码"
]
}
}
}
保存配置文件后,重启 Claude Desktop。
第四步:在 Claude 中使用
重启后,直接在 Claude Desktop 对话框中下达文件操作指令:
示例一:文件查找与摘要
"帮我在NAS的Documents文件夹里找所有2024年的PDF文件,列出文件名"
示例二:批量整理
"把 /Documents/合同/ 里文件名包含'已签'的文件,移动到 /Documents/归档/2024/"
示例三:生成分享链接
"为 /共享/项目提案.pptx 生成一个7天有效期的分享链接"
每次执行操作前,Claude会显示将要执行的具体动作并请求确认,不会自动执行破坏性操作。
4.4 安全注意事项
- 密码安全: 上述配置示例中密码为明文,建议待项目更新更安全的认证方式后再用于生产环境
- 最小权限: MCP账号只开放必要文件夹的访问权限
- 局域网使用: MCP-SynoLink 设计为局域网内使用,不建议暴露至公网
五、三套方案对比与选择建议
| Ollama + DeepSeek | Paperless-AI | MCP-SynoLink | |
|---|---|---|---|
| 核心用途 | 本地AI问答与文件分析 | 扫描件自动识别归档 | AI主动执行文件操作 |
| 部署难度 | ⭐⭐(中等) | ⭐⭐⭐(较复杂) | ⭐⭐(中等) |
| 最低内存要求 | 8GB(7b模型) | 4GB | 无特殊要求 |
| 隐私等级 | 极高(完全本地) | 可配置为完全本地 | 高(局域网内) |
| 适合人群 | 需要AI对话分析文件者 | 大量纸质文件/扫描件用户 | 进阶自动化 + Claude用户 |
| 可组合使用 | ✅ 可作为其他方案的AI后端 | ✅ 可调用Ollama作后端 | ✅ 可结合所有方案 |
推荐上手路径:
- 第一次接触 → 从 Ollama + DeepSeek 开始,30分钟内可跑起来
- 有大量纸质文件 → 加装 Paperless-AI(用Ollama作后端,零额外AI成本)
- 想要AI全面接管 → 最后配置 MCP-SynoLink,三套方案叠加使用
六、结语
2025-2026年,群晖NAS社区正在经历一场自下而上的AI革命。不依赖厂商推送,通过Docker、开源工具和新兴AI协议,家庭用户已经可以在自己的NAS上实现:
- 本地大模型私密问答和文件分析:数据不出局域网
- 文档AI自动归档:扫描件秒变可搜索、已分类的智能档案库
- AI助手主动管理文件:用对话语言完成复杂文件操作
这些方案已在实际使用中经过验证,对于愿意投入一个下午部署调试的用户,回报是一套完全属于自己、不依赖任何外部服务的私人AI基础设施。数据在你手里,AI也在你手里。
如果需求从个人 AI 工作站延伸至多人协同与跨站点同步,可进一步参阅群晖 企事业文件共享 解决方案。
操作步骤
- 1部署 Ollama + DeepSeek-R1SSH 登入 NAS,docker run 启动 ollama 容器映射 11434 端口,ollama pull deepseek-r1:7b 下载模型
- 2部署 Open WebUI 可视化界面docker run 启动 open-webui 容器映射 3000 端口,设置 OLLAMA_BASE_URL 指向本地 11434
- 3对接 AI Console(可选)AI Console → Add Provider → Custom,填 http://localhost:11434/v1 + 模型名 deepseek-r1:7b
- 4部署 Paperless-NGX + Paperless-AIdocker-compose 启动 webserver/db/broker 三件套,获取 API Token,再 docker run paperless-ai 容器接入
- 5配置 MCP-SynoLinkgit clone 项目本地构建,创建专用 DSM 账号,编辑 claude_desktop_config.json 添加 mcpServers 配置,重启 Claude
- 6安全加固MCP 用最小权限账号、不要 admin;Paperless-AI 隐私敏感文件务必走 Ollama 后端不走 OpenAI
常见问题
群晖NAS运行DeepSeek需要什么配置?
推荐使用deepseek-r1:7b版本,需要8GB以上内存和x86-64架构。入门机型(J4125)可用1.5b版本(约3GB内存),高端机型可部署14b。所有NAS都需要安装Container Manager套件。
Ollama可以和群晖AI Console一起使用吗?
可以。AI Console 1.2新增了自定义OpenAI兼容接口选项。在AI Provider设置中填入Ollama的API地址(http://NAS-IP:11434/v1),即可将本地DeepSeek作为AI Console的后端,MailPlus和Office的AI功能都会调用本地模型。
Paperless-AI会把我的文件上传到云端吗?
配置为使用本地Ollama时,文件完全在局域网内处理,不上传任何内容。如果配置为使用OpenAI API,OCR后的文字内容会发送给OpenAI处理。建议隐私敏感文件使用Ollama后端。
MCP-SynoLink需要开放群晖的外网访问吗?
不需要。MCP-SynoLink运行在本地电脑上,通过局域网IP连接群晖DSM,不需要外网穿透或端口映射。建议只在局域网内使用,不要将群晖管理端口暴露至公网。
MCP-SynoLink配置文件中密码是明文的,安全吗?
是一个已知安全风险。建议为MCP专门创建权限最小的账号,只给该账号访问必要文件夹的权限,不要使用admin账号。项目README也建议等待更安全的认证方式更新后再用于生产环境。